Unlocking the Power of Language Models: Understanding LLM Settings
- Jia Min Woon
- Artificial Intelligence, Weave
Language models are the backbone of many AI applications we use every day, from virtual assistants to language translation tools. One type of language model, known as Large Language Models (LLMs), has gained significant attention due to its ability to understand and generate human-like text. However, to make the most out of these LLMs, it’s essential to understand the settings that control their behavior. Here, we’ll delve into five key settings that can help you harness the full potential of LLMs.
Model Size
Imagine a language model as a massive library filled with books, each containing vast amounts of knowledge. The size of the model refers to the number of books it has access to. Larger models have more books, which means they can understand and generate text with greater complexity and nuance. However, larger models also require more computational resources and time to train and use.
For example, in the screenshots from Weave below, different language models have different parameters. Llama2 70B is a 70 billion parameter language model from Meta, Mistral 7B Instruct is a 7 billion parameter language model from Mistral, while Mixtral 8x7B Instruct is a 47 billion parameter language model from Mistral.
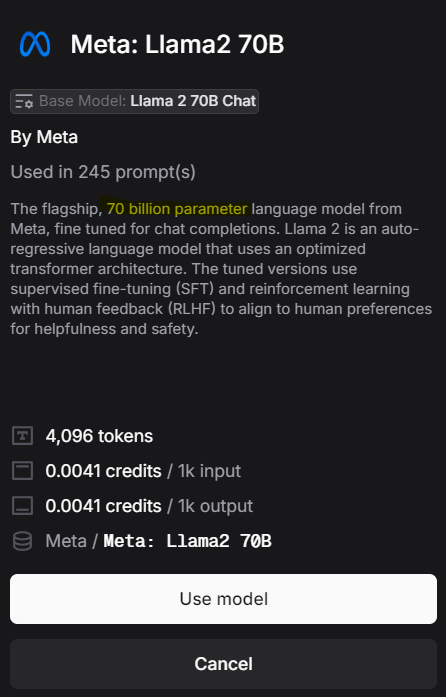
Figure 1: Meta: Llama2 70B
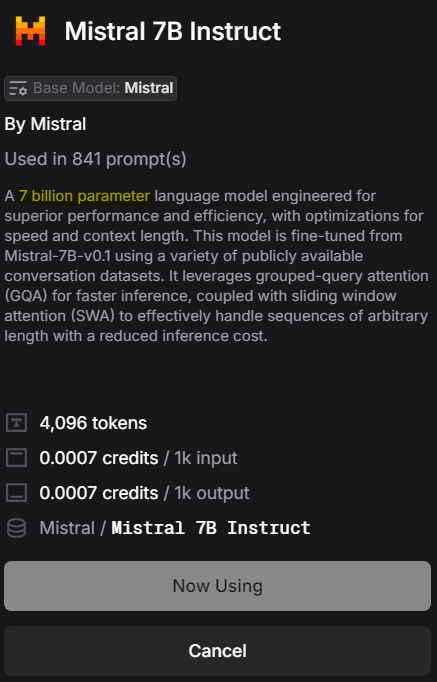
Figure 2: Mistral 7B Instruct
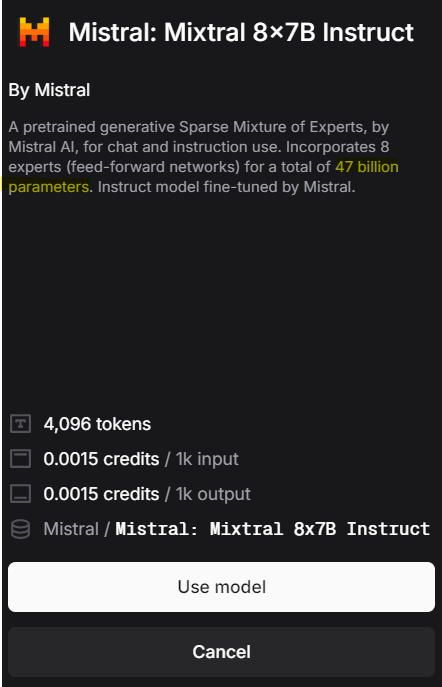
Figure 3: Mistral: Mixtral 8x7B Instruct
Temperature
Temperature is like the spice level in your favorite dish. In the context of LLMs, temperature controls the randomness of the generated text. A low temperature produces more predictable and conservative outputs, while a higher temperature adds a dash of randomness, resulting in more creative and diverse text. It’s all about finding the right balance between coherence and creativity.
Top P (Nucleus) Sampling
Top P sampling, also known as nucleus sampling, is a technique used to improve the quality of generated text. Imagine you’re fishing in a pond filled with words, and each word has a different likelihood of being caught. Top P sampling sets a threshold probability, and only words with probabilities above this threshold are considered. This helps prevent the generation of irrelevant or nonsensical text, resulting in more coherent outputs.
Max Tokens
Think of max tokens as a limit on the number of words the language model can generate in a single output. Just like the character limit of X, formerly known as Twitter, max tokens ensure that the generated text remains concise and to the point. Setting an appropriate max tokens value is crucial to control the length of the generated text and avoid overwhelming the user with unnecessary information. For example, when set to 4,096 tokens, the chat completion will stop at the 4,096th token.
Enable / Disable Sampling
When sampling is enabled, the model is allowed to generate text independently based on its learned knowledge. However, when disabled, the model may rely more on copying input text or following predefined rules. Enabling sampling can lead to more diverse and creative outputs, while disabling it may result in more conservative and predictable text generation.
There are two types of sampling:
Top P Sampling: This method selects the next word from a smaller group of the most likely words. The selection is based on a cumulative probability threshold “P.” This means the model looks at the most probable words it could use next and keeps adding them up until their combined chance reaches a threshold, like 90% probability. This ensures that the choices made are neither too random nor too predictable.
Top K Sampling: The model limits its choice to the “K” most likely next words. For example, if K is 10, the model only considers the top 10 probable next words it could use. This approach simplifies the decision process by reducing the number of options to a fixed number, focusing only on the most likely candidates.
Users can determine the value of top p and top k in LLM only when sampling is enabled.
Advanced Customization
While these settings offer a gateway to tailoring AI outputs, they are but a glimpse into the vast potential of large language models. The real magic lies in the harmonious tuning of these parameters, crafting responses that resonate with the task at hand, be it the precision of code generation or the whimsy of creative writing.
Weaving It All Together with Weave
As we explore the intricate dance of the elements mentioned above, it’s essential to consider platforms like Weave that streamline the application of these settings. Weave offers an intuitive environment where practitioners can effortlessly adjust these parameters, ensuring their models are finely tuned for specific tasks and applications. By harnessing the power of Weave, users can transcend the basic configurations, venturing into a realm of optimized AI that’s both accessible and effective for a myriad of use cases.
- Dynamic Adjustment: Adapting these settings in real-time based on the context of the interaction, ensuring that the AI’s responses are not just accurate but also contextually appropriate.
- Task-Specific Tuning: Tailoring these parameters for specific applications, such as creative writing, technical analysis, or customer service, optimizing the balance between creativity, relevance, and precision.
- Feedback Loops: Incorporating user feedback to iteratively refine these settings, enhancing the model’s performance and user satisfaction over time.
In this exploration, we’ve traversed the landscape of LLM settings, uncovering the levers that guide the engines of artificial creativity. As we stand at the intersection of technology and artistry, it’s clear that the future of AI is not just in the algorithms but in how we choose to wield them, with platforms like Weave playing a pivotal role in this journey. Try experimenting on these settings on Weave now!